本文共 5051 字,大约阅读时间需要 16 分钟。
想起之前学习redis做的笔记乱七八糟,有时候回顾一下都比较难,现在就像整理一下发布,然后借此回忆一下reids
1基础
1.1redis
- 提供海量数据存储访问
- 数据存储在内存里,读取更快
- 非关系型、分布式、开源、水平扩展
- NoSql
- 分布式缓存中间件
- key-value存储
1.2Nosql简介
- Not Only Sql
- 传统项目使用纯数据库
- 为互联网和大数据而生
- 水平(横向)扩展方便高效
- 高性能读取、高可用
- 一般存数据,做缓存
1.3缓存方案对比
1.3.1Ehcache=》适合单应用
优点:
- 基于java开发
- 基于JVM缓存
- 简单、轻巧、方便
缺点:
- 集群不支持
- 分布式不支持
1.3.2Memcache
优点:
- 简单的key-value存储
- 内存使用率比较高
- 多核处理,多线程
缺点:
- 无法容灾=》重启后之前数据无法恢复
- 无法持久化
1.3.3Redis
优点:
- 丰富的数据结构
- 持久化
- 主从同步、故障转移,
- 内存数据库
缺点:
- 单线程
- 单核
2安装Redis
2.1linux安装
1.首先去官网下载

2.进入到指定文件位置,解压
tar -zxvf redis-6.0.9.tar.gz#解压说明 tar -zxvf 文件全称

3.进入redis文件夹
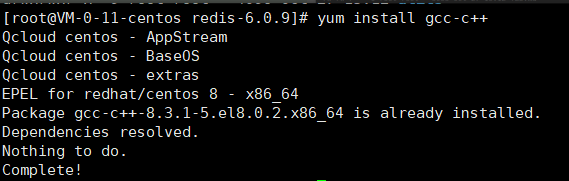
4.安装redis之前需要安装一个依赖: yum install gcc-c++
5.开始安装redis,先make编辑

6.开始安装: make install ;安装完成之后需要配置redis,先进入 utils文件夹下

7.然后拷贝redis的启动脚本,拷贝到/etc/init.d/文件夹下:
cp redis_init_script /etc/init.d/
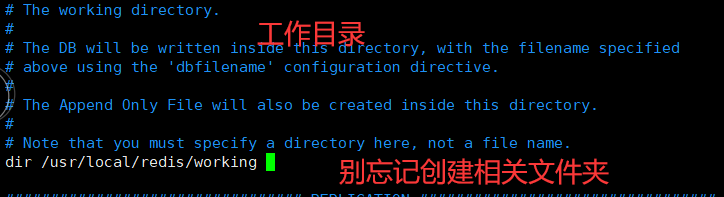
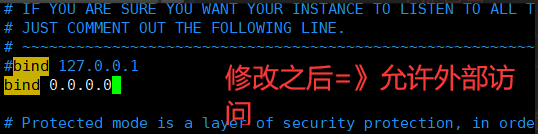
8.再把redis文件夹下的redis.conf拷贝到/usr/local/redis 下;然后进入/usr/local/redis 文件夹下 ,修改redis.conf => vim redis.conf

9. 配置相关信息:,设置完毕之后按 ESC 输入 :wq! 回车
daemonize 修改no

10.设置redis启动脚本


11.给脚本设置权限。然后启动: ./redis_init_scrip start


2.2常见安装错误

需要更新gcc
1、安装gcc套装:yum install cppyum install binutilsyum install glibcyum install glibc-kernheadersyum install glibc-commonyum install glibc-develyum install gccyum install make2、升级gccyum -y install centos-release-sclyum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutilsscl enable devtoolset-9 bash3、设置永久升级:echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
3redis基础
3.1常见命令
#关闭redisredis-cli -a password shutdown#关闭redis./redis_init_script stop#进入redis客户端redis-cli#输入密码auth pwd#设置缓存set key value 例如 set id 12#获取缓存get key 例如 get id#删除缓存del key 例如 del id#查看是否存活redis-cli -a password ping
3.2redis类型
3.2.1 string字符串
string:最简单的字符串类型键值对缓存,也是最基本的key相关keys* :查看所有的key (不建议在生产上使用,有性能影响)type key : key的类型string类型get/setdel :查询设置/删除set rekey data:设置已经存在的key ,会覆盖setnx rekey data :设置已经存在的key ,不会覆盖set key value ex time :设置带过期时间的数据expire key :设置过期时间ttl:查看剩余时间,-1永不过期,-2过期append key :合并字符串strlen key :字符串长度incr key :累加1decr key :类减1incrby key num :累加给定数值decrby key num:累减给定数值getrange key start end :截取数据, end=-1代表到最后setrange key start newdata :从start位置开始替换数据mset :连续设值mget :连续取值msetnx :连续设置,如果存在则不设置其他select index :切换数据库,总共默认16个flushdb :删除当前下边db中的数据flushall :删除所有db中的数据
3.2.2hash
hash :类似map ,存储结构化数据结构,比如存储一 个对象(不能有嵌套对象) 使用hset key property value :-> hset user name 2233->创建一个user对象,这个对象中包含name属性, name值为2233hget user name :获得用户对象中name的值hmset:设置对象中的多个键值对-> hset user age 18 phone 139123123hmsetnx :设置对象中的多个键值对,存在则不添加-> hset user age 18 phone 139123123hmget :获得对象中的多个属性-> hmget user age phonehgetall user :获得整个对象的内容hincrby user age2 :累加属性hincryfloat user age 2.2 :累加属性hlen user :有多少个属性hexists user age :判断属性是否存在hkeys user :获得所有属性hvals user :获得所有值hdel user :删除对象
3.2.3list
list:列表,[a,b,c...]. 使用lpush userList 1 2 3 4 5:构建一-个list, 从左边开始存入数据rpush userList 1 2 3 45 :构建一-个list ,从右边开始存入数据lrange list start end :获得数据lpop:从左侧开始拿出一一个数据rpop:从右侧开始拿出一一个数据pig cow sheep chicken ducklien list : list长度lindex list index :获取list下标的值lset list index value :把某个下标的值替换linsert list before/after value :插入-一个新的值Irem list num value :删除几个相同数据ltrim list start end :截取值。替换原来的list
3.2.4zset
sorted set :排序的set ,可以去重可以排序,比如可以根据用户积分做排名,积分作为set的一一个数值,根据数值可以做排序。set中的每- -个memeber都带有-一个分数
使用
使用zadd zset 10 value1 20 value2 30 value3 :设置member和对应的分数zrange zset 0-1 :查看所有Zset中的内容zrange zset 0-1 withscores :带有分数zrank zset value :获得对应的下标zscore zset value :获得对应的分数zcard zset :统计个数zcount zset 分数1 分数2 :统计个数zrangebyscore zset 分数1 分数2 :查询分数之间的member(包含分数1分数2)zrangebyscore zset (分數1 (分数2 :查询分数之间的member (不包含分数1和分数2 )zrangebyscore zset 分数1 分数2 lmit start end:查询分数之间的member(包含分数1分数2)。获得的结果集再次根据下标区间做重询zrem zset value :删除member
yml配置文件代码 application.yml
#tomcat 配置server: port: 8899 servlet: context-path: /spring: redis: database: 1 host: 127.0.0.1 port: 6379# password: 没有就可以不写
controller代码
package com.item.redisDemo;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestController@RequestMapping("/redis")public class DemoRedisController { @Autowired private RedisTemplate redisTemplate; @GetMapping("/set") public Object set(String key, String value) { redisTemplate.opsForValue().set(key, value); return "Ok"; } @GetMapping("/get") public Object get(String key) { String o=(String) redisTemplate.opsForValue().get(key); return o; } @GetMapping("/delete") public Object delete(String key) { redisTemplate.delete(key); return "0k"; }} 请求示例


5缓存相关
5.1缓存穿透
查询的key在redis中不存在,对应的id在数据库也不存在。此时被非法用户进行攻击,大量的请求会去数据库(DB)造成宕机,从而影响整个系统。这种现象称之为 缓存穿透;比如请求id是999的数据,redis和数据库都不存在,由于redis没有,每次都会去请求数据库
解决方法:缓存redis把空的数据也缓存到redis中,比如空字符串,空对象等;【999,""】这样,即便数据库没有也返回一个空值
5.2缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存雪崩一般只能缓解,不能杜绝;
解决方式:缓存永不过期、过期时间错开(避免大量缓存同一时间过期)、多缓存结合(redis、Memcache)【先请求redis,没有就去Memcache】、采购第三方redis(比如阿里云)

转载地址:http://qaexz.baihongyu.com/